
Hi! I am Martins Zaumanis, a scientist at Empa Concrete and Asphalt laboratory in Switzerland. Together with Mohammad Abbas we are working on a database for asphalt test results. We will use it to build machine-learning models that can predict asphalt performance. This will significantly reduce the need for physical testing and might even allow designing better-performing asphalt mixtures.
The development of AsphaltMine is funded by the Swiss National Science Foundation project No.213163 within the Project Fate of Polymers in Recycled Asphalt.
The Vision
Our vision is that AsphaltMine becomes a perpetual asphalt community project that is continuously collecting new data, building new tools and updating the existing ones.
The Objective
The project’s objective is to enable predicting laboratory test results from results at a lower scale. For example, predicting the rutting test result from the component material test results and their proportions.
Join us!
We can not do this alone! Please join us in the creation of AsphaltMine by contributing performance-based test results. In return, you will get access to the developed prediction tool. And we will have fun co-creating the future of asphalt 🙂
If you would like to participate in the project, please contact me through email [email protected] or by phone +41 58 765 60 75. We will set up a meeting to discuss the details.
How it will work: the short version
To achieve the objective, the following steps are defined:
- Create an organized online database.
- Collect laboratory test results from laboratories across Europe.
- Develop a machine-learning-based tool for predicting laboratory test results.
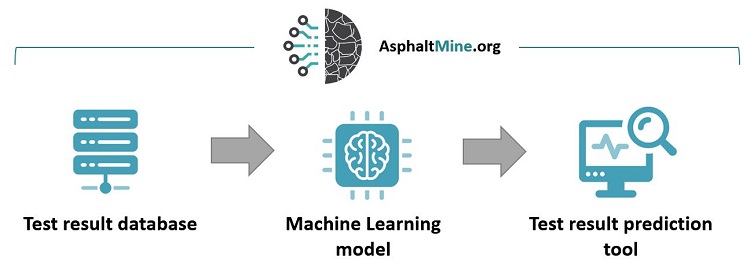
For more details on each step, continue reading. You can also download a PowerPoint presentation here.
Organized Web Database
As the first step, we have built a structured web database for uploading asphalt rutting test results and all the mix component material test results. You can see the structure here.
To ensure that the database can be used across different European countries, we built it according to the EN standards.
Depending on the requirements of each partner, an individual data sharing agreement will be prepared to ensure your data is handled in the way you prefer.
What results are we collecting?
In the first stage of the project, we would like to collect wheel tracking test results (all methods), Marshall test and indirect tensile strength results results along with the respective mixture designs and component material test results. Additionally, we are collecting results for the thermal stress restrained specimen test (TSRST), uniaxial tension stress test (UTST)and stiffness test.
The more results we collect, the better the prediction tool will be. We are open to your suggestions for other test methods we should include in the database.

Who is participating?
The data will be contributed by various institutions, including private companies, research labs and universities. See the current participants and join AsphaltMine here.
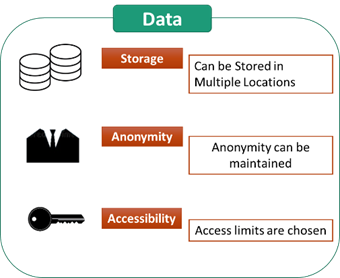
How will the data be shared?
The web-based platform allows to fully customize the access rights.
If you not wish to share the results publicly, they will remain undisclosed forever.
Undisclosed results will only be used for building the prediction tool but will not be shared with public.
See more information about the access of the data and the machine learning model below.

It is important that only reliable results are collected.
Unsatisfactory test results (samples that don’t pass the requirements) should also be included in the dataset. You can choose not to disclose them to the public.
How will the database work?
The database will be built using a platform called “Configurable Data Curation System“. This system is built for data curation, it is free and open-source.
The asphalt test results will be stored in a XML tree-like format and organized in a way that allows simple filtering. Downloading and converting back to a Excel format will also be possible.
How to upload the data?
The user can upload the results in two ways:
- Using a web form.
- For standardized test result protocols (pdf or Excel files), we can develop a plug-in for automatic uploading. This has to be done on a case-by-case basis.
Where is the data stored?
By default, the data will be stored on a server in Switzerland, but the database functionality allows remote storage if needed.
We will prepare a contract where the data handling is described.
Machine-Learning Model
How will we build the machine-learning tool?
Once we have collected enough data in the database, we will train machine-learning models that allow predicting laboratory test results.
Initially, several algorithms will be employed until we identify the one with the best accuracy. We might also augment the tool with established physical materials science relationships.
What is there is not enough data?
This is a project that has not been done before so we expect difficulties and limited data availability is among the top concerns. Here are some of the challenges we expect and how we plan to address them.
| Possible challenge | Planned solution |
| Different test procedures are used by different labs. | Our database is built according to standard EN test methods. Additional fields are available in the database for describing particular features of the tests. |
| Incomplete data for a particular test. | We expect missing data. We might use known physical materials science relationships to augment the data. We can also filter the results that have the required characteristics. |
| Not enough test results. | We will approach different labs to gather more data. Your suggestions for new participants are very welcomed. Please write me. |
| The existing component material test methods (e.g. penetration or softening point) do no allow accurate prediction of the mixture performance. | For select test result suppliers, we will run additional DSR-based tests, including BTSV and MSCRT. Other tests might be added, as necessary. |
Test Result Prediction Tool
After creating the machine learning tool, we will make it available through this website. Let’s call it the “Test Result Prediction Tool”.
You will have to enter information about the mixture design. Then on a click of a button the prediction tool will calculate the expected test result, for example the rutting test result.
What can the prediction tool be used for?
Initially, a rutting test result prediction tool will be developed using the collected results. The tool can be used to:
- Predict the test results from the mix recipe.
- Reduce the testing costs and save time since multiple recipes can be virtually tested before committing to a physical lab test.
- Optimize the mixture recipe to reduce production costs and improve performance.
Prediction tools for other test methods will be added at later stages.
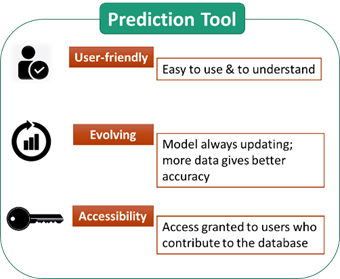
How will the tool be accessed?
We will develop a web-based platform for using any tools we develop. It will be available through this very AsphaltMine website. We will make sure the tools have a user-friendly interface.
Who gets the right to use the tool?
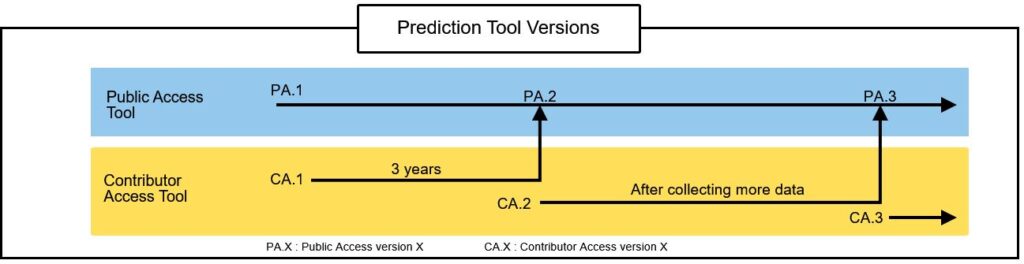
The prediction tool access is fully customizable. Below is our initial offer for the data and prediction tool sharing principle for two prediction tool versions:
- Public access prediction tool built using the open access data. The tool will be freely available on the AsphaltMine website.
- Contributor access prediction tool built using the entire data, including undisclosed data. All the contributors whose data is used for training the machine-learning model will have access to the “Contributor Access” tool. After 3 years, the RV tool will become available for public access.
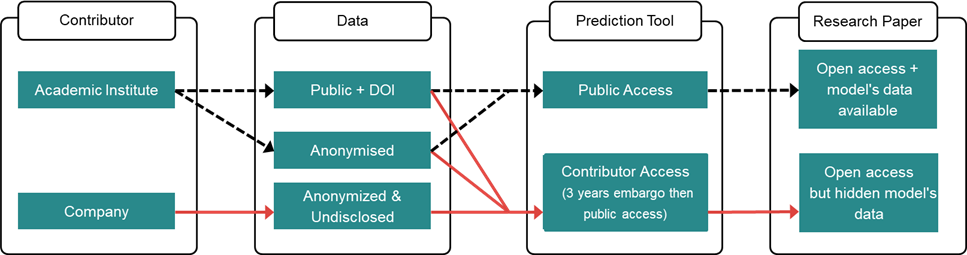
What about the data submitted after the tool is published?
New versions of the tool can be developed once a considerable amount of new data is added, hence the numbers in the figure below.
In the figure you can also see how we plan to handle the access rights of the two versions of the tool over time.
About the AsphaltMine project
Who is sponsoring the work?
The initial work for the creation of the database creation is funded through the Swiss National Science foundation project No.213163 which will last for 4 years (link). It is part of a collaborative project with University of Antwerp and Vienna University of Technology.
I am open to jointly exploring other funding opportunities for further work on the idea.
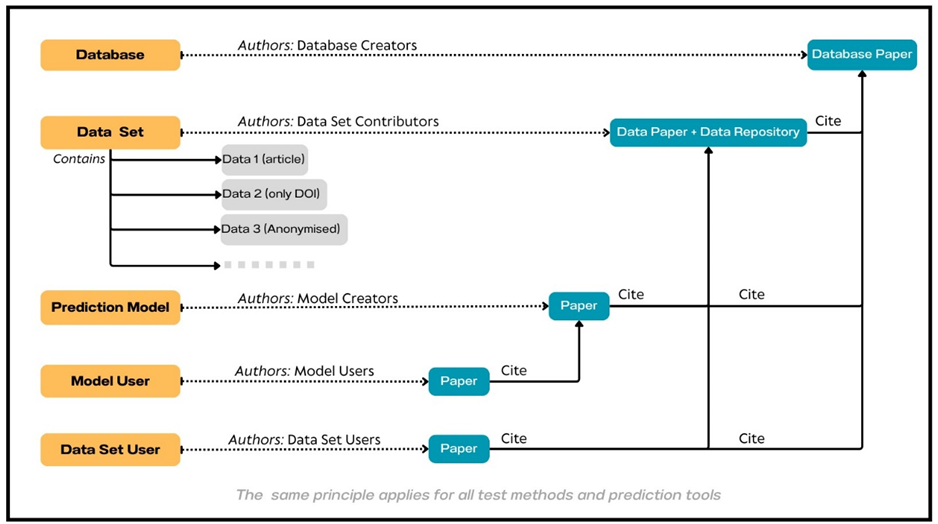
Who will be the authors?
We propose the following approach for authorship and citing of the sources:
How long will it take?
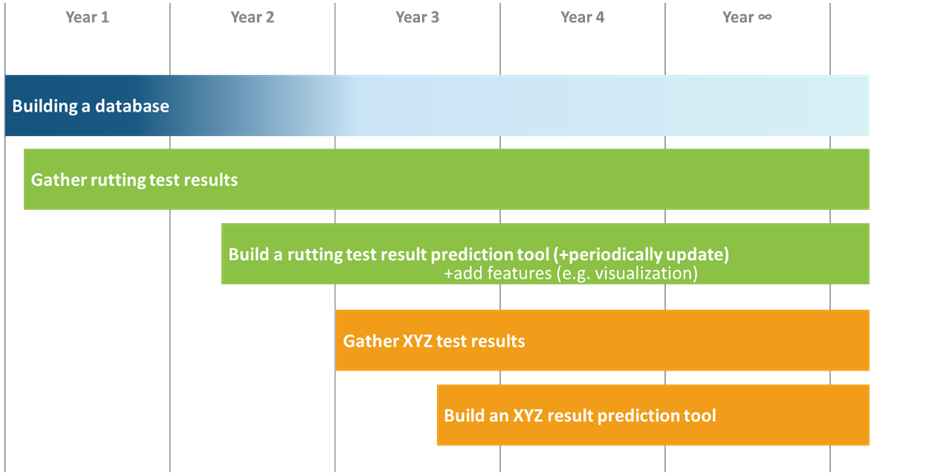
We expect to have a prediction tool for rutting test in year 2. If successful, we will continue the work on the database and add new prediction tools later on.
Who is doing the work?
Martins Zaumanis is the project principal investigator. Scientist at Empa, Switzerland.
Mohammad Abbas will do the main work on the database and the creation of machine learning model. Postdoc at Empa, Switzerland.
Marko Oreskovic is volunteering his knowledge and energy to help the project succeed. Assistant professor at the University of Belgrade, Serbia.
Partners of the SNSF research project from the Antwerp University and TU Wien are contributing their expertise and resources to the building and population of the database.
Are you in?
We hope you will commit to sharing test results with us. We know it is significant work, but we believe it will be worth it to reduce testing costs and improve the mixture performance.
If you would like to participate in the project, please contact me through email [email protected], by phone +41 58 765 60 75, or on this website through the contact form. We will set up a meeting to discuss the details.